Introduction > Installation > Various installations
Installation: Speech synthesis only
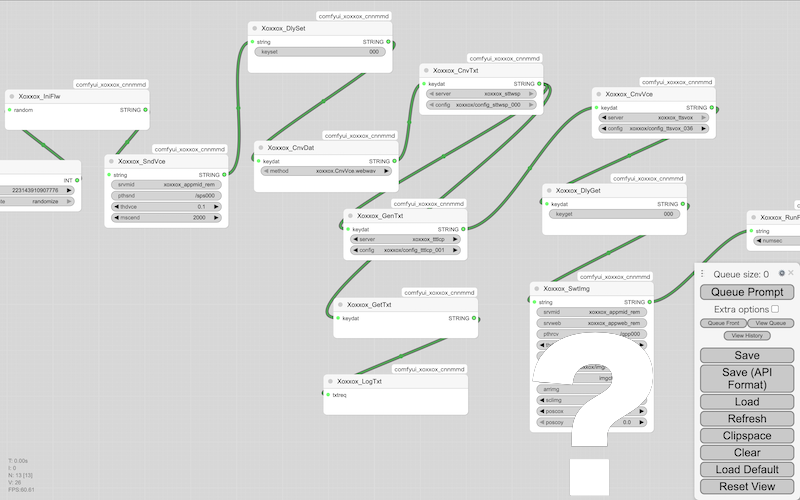
It's a simple process of making a character speak using the text you enter: [※1]
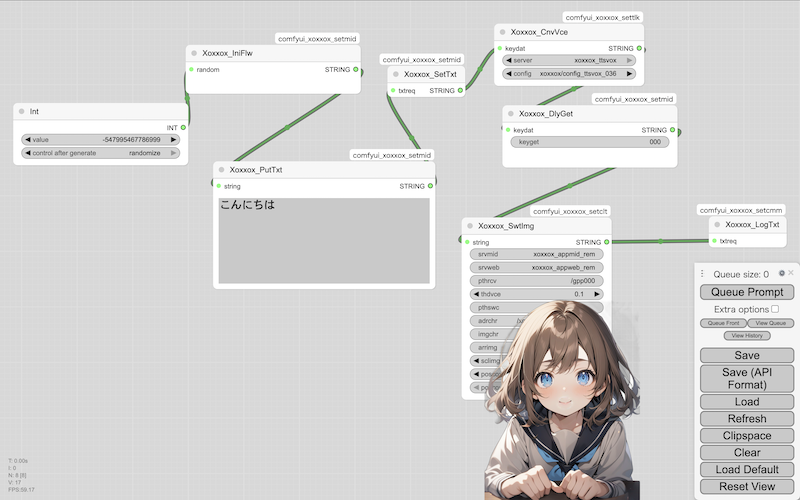
- ・
- Server startup & workflow: cnnmmd_xoxxox_mgrcmf_cmf_txt_vox_001
- ・
- Client settings ~ Start: cnnmmd_xoxxox_appcmf
Setup and launch in two steps:
$ yes | ./manage.sh create cnnmmd_xoxxox_mgrcmf_cmf_txt_vox_001 -d $ yes | ./manage.sh launch cnnmmd_xoxxox_mgrcmf_cmf_txt_vox_001 -d
- *1
- This flow does not have auto-recurrence (you need to press a button to run the flow after each text entry).
Installation: Voice recognition and voice synthesis
This flow doesn't require a language generation model - if what you say matches one of the keywords in the configuration file, the character will say the corresponding phrase (in the order listed or randomly):
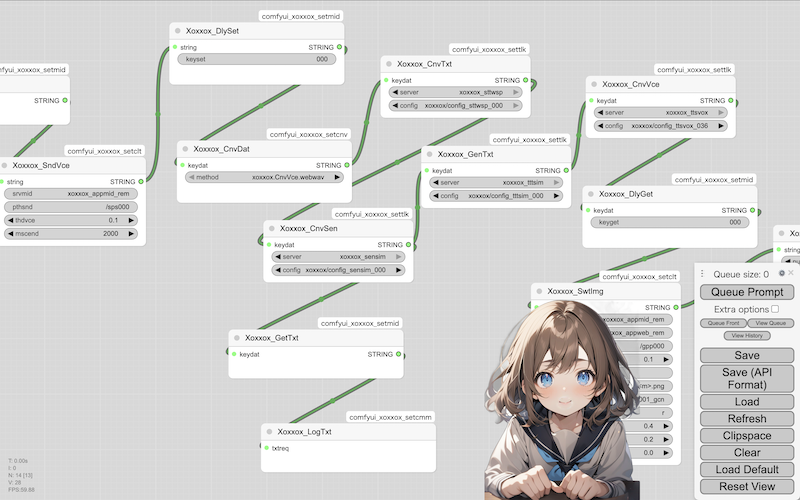
- ・
- Server startup & workflow: cnnmmd_xoxxox_mgrcmf_cmf_sim_wsp_vox_001
- ・
- Client settings ~ Start: cnnmmd_xoxxox_appcmf
Setup and launch in two steps:
$ yes | ./manage.sh create cnnmmd_xoxxox_mgrcmf_cmf_sim_wsp_vox_001 -d $ yes | ./manage.sh launch cnnmmd_xoxxox_mgrcmf_cmf_sim_wsp_vox_001 -d
A sample configuration file looks like this - pseudo-sentiment analysis is a list of keywords (regular expressions) to match:
{
"except": "0",
"dicsen": {
"1": "happy|fun",
"2": "sad|lonely"
}
}
The pseudo-language generation is a list of responses to the results of sentiment analysis (the numbers "1" and "2"):
{
"output": "random",
"dictxt": {
"0": [
"you know"
],
"1": [
"I'm happy, right?"
"It's fun."
],
"2": [
"Sad, isn't it?"
"It's lonely, isn't it?"
]
}
}
Even without a sentiment analysis model or language generation model, you can create various conversation scenes yourself.
Installation: Scripted Workflow
This is a scripted (CLI) workflow - with this configuration, you don't need a GUI workflow creation environment (ComfyUI): [※1][※2]
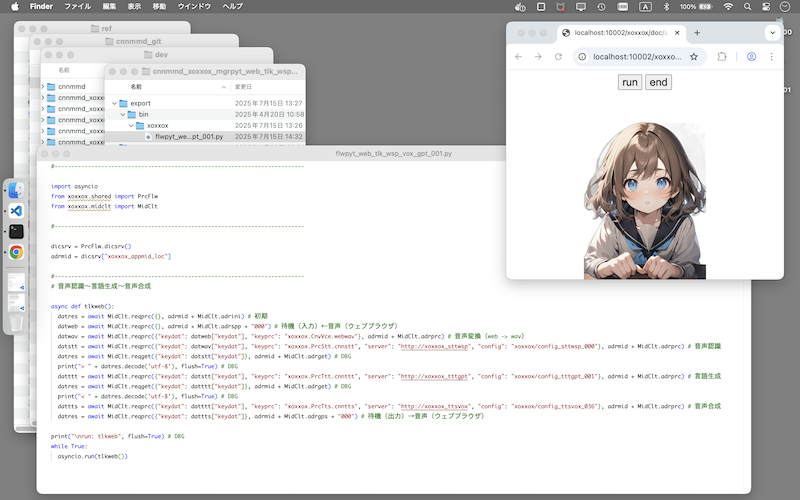
- ・
- Server startup & workflow: cnnmmd_xoxxox_mgrpyt_web_tlk_wsp_vox_lcp_001
- ・
- Client settings and startup: cnnmmd_xoxxox_tlkweb
Setup and launch in two steps:
$ yes | ./manage.sh create cnnmmd_xoxxox_mgrpyt_web_tlk_wsp_vox_lcp_001 -d $ yes | ./manage.sh launch cnnmmd_xoxxox_mgrpyt_web_tlk_wsp_vox_lcp_001 -d
On the web browser side, follow the client-side steps above to set up and launch the application.
- *1
- The GUI workflow simply calls these script-based relay handlers (dynamic code) from the nodes.
- *2
- Each function is called directly from the programming language (Python), so there are no limits to the degree of freedom (order, branching, repetition), and you can even create these functions yourself (Python class + dictionary format).
Setup: Speech recognition, speech synthesis, and language generation (natural intonation)
This is a conversation with a speech synthesis model that can more naturally reproduce Japanese intonation: [※2][※F]

- ・
- Server startup & workflow: cnnmmd_xoxxox_mgrcmf_cmf_tlk_wsp_vit_lcp_001
- ・
- Client settings ~ Start: cnnmmd_xoxxox_appcmf
Setup and launch in two steps:
$ yes | ./manage.sh create cnnmmd_xoxxox_mgrcmf_cmf_tlk_wsp_vit_lcp_001 -d $ yes | ./manage.sh launch cnnmmd_xoxxox_mgrcmf_cmf_tlk_wsp_vit_lcp_001 -d
- *2
- Although the latency is greater than with the faster speech synthesis model (VOICEVOX), if you can allocate 12-16 GB of memory to the container, you will get a reasonable response speed.
- ※F
- As announced, we will be replacing the speech synthesis model (we believe we have almost certainly found similarities with the performers ) ← The natural intonation of this model demonstrates the power of SBV2, but we do not know the source data - if any similarities with performers are found, we will replace it with another model.
Installation: Speech recognition, speech synthesis, and language generation (male character)
This is the conversation flow with the male character: [※1]
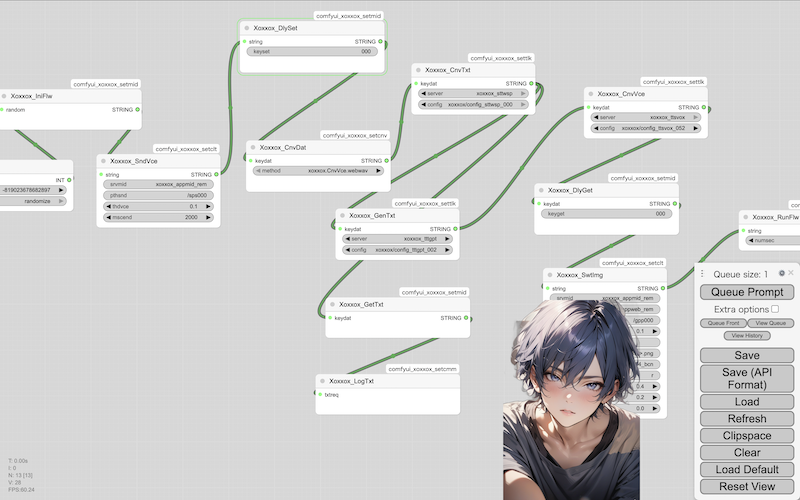
- ・
- Server startup & workflow: cnnmmd_xoxxox_mgrcmf_cmf_tlk_wsp_vox_lcp_002
- ・
- Client settings ~ Start: cnnmmd_xoxxox_appcmf
Setup and launch in two steps:
$ yes | ./manage.sh create cnnmmd_xoxxox_mgrcmf_cmf_tlk_wsp_vox_lcp_002 -d $ yes | ./manage.sh launch cnnmmd_xoxxox_mgrcmf_cmf_tlk_wsp_vox_lcp_002 -d
Supplement: Unrestricted conversation
If you don't want to be limited in the content of your conversation, you might be able to use the following model and service for Japanese language generation: [※1]
- ・
- cnnmmd_xoxxox_tttlam [*2]
- ・
- cnnmmd_xoxxox_tttnai [*3]
- *1
- Neither of these has large parameters, so some adjustments will be necessary to eliminate any awkwardness in the responses (even the current sample has moderate prompts).
- *2
- This model requires a GPU to run.
- *3
- On a normal PC (without a GPU), this service may be usable to a certain extent if combined with an appropriate speech synthesis model.